The Google File System #
https://research.google/pubs/pub51/
https://pdos.csail.mit.edu/6.824/papers/gfs.pdf
http://nil.csail.mit.edu/6.824/2021/papers/gfs-faq.txt
Colossus(next-gen GFS [2010]):
- https://cloud.google.com/blog/products/storage-data-transfer/a-peek-behind-colossus-googles-file-system
- https://queue.acm.org/detail.cfm?id=1594206
- https://levy.at/blog/22 (👈highly recommend)
TL;DR #

动机:为了满足 Google 日益增长的存储需求,特别是大文件、多并发读写的场景。
目标:跟大多数分布式系统一样,都希望达到高性能、可扩展性、稳定性和可用性。
GFS 与传统分布式存储需求不同的点在于:
- 组件失效要比其他任何异常都更加常见,因此系统必须要有持续监测、错误检测、容错机制以及自动恢复的能力 。
- 文件大小对于传统规格来说非常大,GB 以上的文件非常多。
此文写于 2003 年,在 17 年后的今天,一个电影就已经几 GB,见怪不怪了除此之外,大文件的读写操作要比小文件多得多,系统应能够支持管理小文件,但不一定要对其做特殊优化。 - 大部分文件写操作都为追加写,而不是覆盖写。因此追加写的性能以及原子性保证成为系统的主要目标。
- 应用和文件系统 API 的共同设计能够有效提升整个系统的弹性。
设计总览 #
假设 #
- 系统建立在便宜的商用硬件上,这些组件可能会经常失效。
- 系统要能存储一定量的大文件,预计有几百万文件,大多在 100MB 及以上。几 GB 的大文件也非常常见,系统必须能够有效地管理它们。
- 系统负载主要为这两种读取方式:较大的流式读取(large streaming reads)以及较小的随机读取(small random reads)。
- 负载中有较多的大量顺序追加写入情况。当数据被写入后,很少会被修改。
- 系统需要高效地实现追加写情况下的并发语义。
- 持续的高吞吐能力要比低延迟更为重要。
接口 #
尽管 GFS 并没有实现 POSIX 接口定义,GFS 仍提供了与其他文件系统类似的接口。文件是由目录层级管理,且由路径(pathname)进行唯一标识。GFS 支持如新建、删除、打开、关闭、读取、写入的操作。
除此之外,GFS 还有 快照(snapshot) 和 记录追加(record append) 这两种操作:
- 快照:以最低损耗复制一个文件或目录。
- 记录追加:多个客户端可以并发写入同一个文件,由 GFS 来保证并发操作的原子性。
架构 #
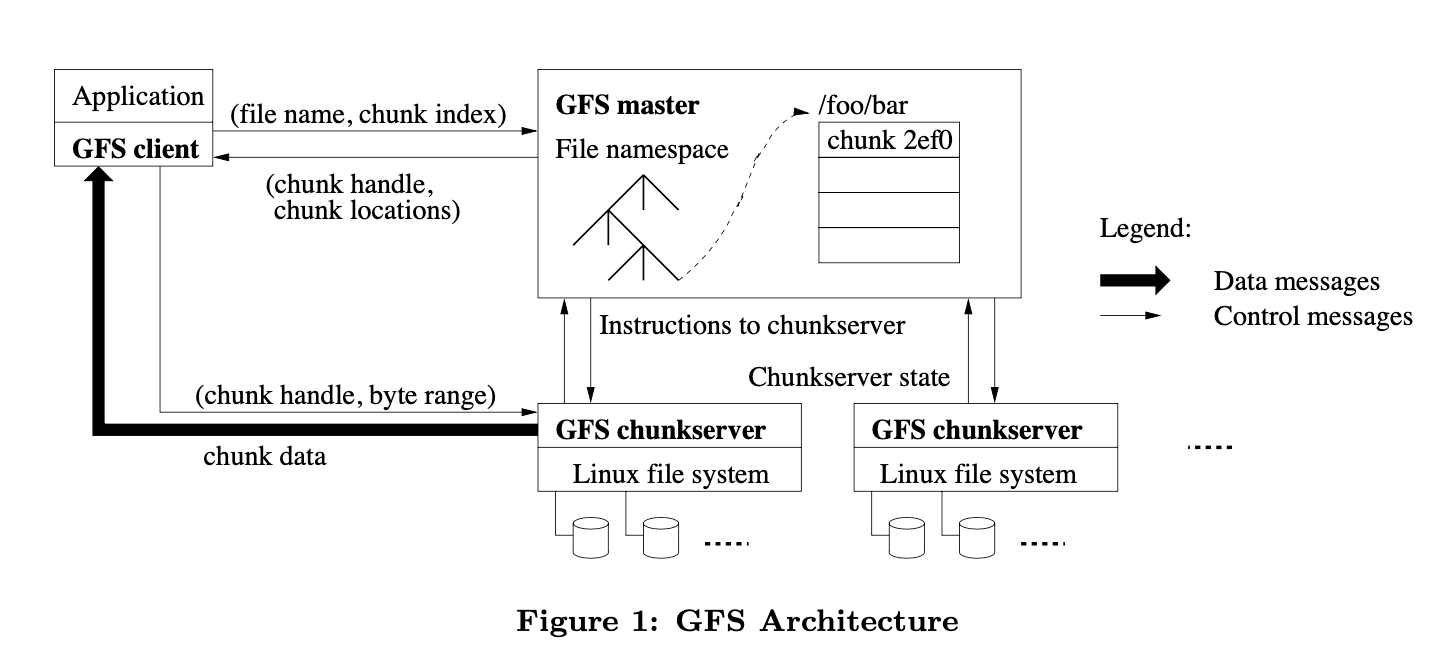
GFS 主要以三个组件组成:
- master:单一控制器,保存了整个系统的元数据,并处理所有读写请求。
- chunkserver:数据块服务器,按照块(chunk)在本地磁盘中存储数据,是真正存储数据的组件。
- client:GFS 客户端,发起读写请求。
文件会被拆成固定大小的数据块(chunks)。每个数据块在新建的时候,都会被 master 赋予一个 64 位的全局唯一的块句柄(chunck handle)(与文件句柄 fd 类似)。每个数据块都存在副本并分布在多个 chunkserver 上。默认情况下,副本数为 3 ;用户也可以对不同的文件命名空间区域声明(设置)不同的副本等级。
master 会保存文件系统中所有的元数据(命名空间,权限控制,文件至数据块的映射,以及数据块的当前位置),还会管理整个系统中的活动(块租用管理 lease management ,孤立块的垃圾回收,以及块数据迁移)。
master 通过周期性的心跳消息 HeartBeat 来给 chunkserver 下发命令和收集状态。
GFS 的客户端若需要做读写操作,会先给 master 发送读写请求,所有承载真正数据的通信都直接跟 chunkserver 建立。
client 和 chunkserver 都不会缓存任何数据(client 只会缓存元数据),原因如下:
- 由于文件都非常大,客户端缓存的收益非常小(cache hit rate 很低)。不做缓存能够极大降低系统复杂度且不会产生缓存一致性问题。
- chunkserver 不需要额外定义应用缓存规则,因为所有的数据块都存储在本地磁盘,直接使用 Linux 的 buffer cache 即可。
单主(Single Master) #
单主模型极大简化了系统,也能让 master 能够通过全局知识(global knowledge)进行复杂的数据块替换以及副本的决策。然而,为了不让 master 成为瓶颈,必须要尽可能减少其在读写操作中的参与度。因此,在 GFS 设计中,client 从不通过 master 直接读取数据,master 只告知 client 目标数据的位置,由 client 直接与相应的 chunkserver 交互进行读写(一般会寻找最近的 chunkserver,这里可以定义块负载均衡的算法)。一旦 client 从 master 获取到某个文件的元数据,client 会将其在本地缓存一段时间,以减少与 master 的交互次数,减轻 master 的负载。
数据块大小(Chunk Size) #
数据块大小是 GFS 的设计核心之一,选择的值是 64 MB(比大多数文件系统的数据块大小都要大,常用的 Block size 一般为 512B 或 4KB)。
较大的数据块大小带来的好处:
- 降低 client 和 master 的交互次数(一个块的元数据就可以供 client 读取 64 MB 的数据)。
- 由于块较大,client 每次读取 64 MB 的数据只需要一个 TCP 连接,而不用多次建立连接读取多个小数据块,这也降低了网络开销。
- 减轻了 master 存储元数据的压力,数据块变大,元数据数目就会变少。
较大数据块大小的不足:
- 小文件占用的空间较大,一个不足 64 MB 的文件也需要占用一个数据块的大小。
- 数据块较大,可能会形成热点数据块(client 大多请求某个特定的文件)。在实际运行中,作者发现热点数据并不是一个特别需要担心的问题(除了一开始 GFS 被用于批量队列系统),因为大部分应用都会顺序读取大文件,而不会集中于读取某几个文件。
- https://benohead.com/blog/2011/11/07/determine-the-block-size-on-a-file-system/
- https://stackoverflow.com/questions/8537579/file-system-block-size
元数据 #
master 存储三种类型的元数据,分别是:
- 文件及数据块的命名空间。
- 文件到数据块的映射关系。
- 数据块副本的存储位置。
其中,命名空间与映射关系会被记录到 master 的内存以及操作日志(operation log)中,而数据块副本的存储位置仅会被记录与内存中,并不对其做持久化。
当 master 启动或有新的 chunkserver 加入集群时,master 会去询问 chunkserver 其数据块副本的位置情况。
内存数据结构 #
master 将元数据都存储于内存中,就能够高效地周期性遍历整个集群的状态(比存磁盘高效)。周期性扫描用于实现数据块垃圾收集、数据块重复制(chunkserver 失效)、数据块迁移以平衡磁盘负载和平均磁盘空间。
一个 64 MB 的数据块元数据大小在 64 B 左右,且因为使用了前缀压缩,命名空间的数据要更小。即使如此,若集群增长,master 的内存无法容纳这么多元数据,为了保持架构的简单性、可靠性、弹性和优越的性能,我们只需简单提高 master 机器内存即可 这方案真粗暴 。
数据块位置 #
master 并不对数据块位置信息进行持久化,而是通过周期性地给 chunkserver 发心跳请求来更新数据块的位置信息。这样设计的原因是 master 无法决定数据块位置信息(如 chunkserver 很可能失效),因此仅将该信息存储于内存中,并不做持久化。
操作日志 #
操作日志包括了 GFS 系统中重大的元数据改变记录。因此它是 GFS 的中心。因此操作日志需要可靠地存储下来,因此它会备份到多个远端服务器,且只有在本地和远端的日志刷新之后,master 才会给客户端返回结果。
在刷新日志前,本地的日志会简单做个整合,这样可以降低给系统吞吐带来的影响。
若 master 失效,则备份 master 需要通过重做操作日志来回滚系统状态。为了降低失效后的启动时间,我们必须要让重做的操作日志最小。因此引入了 checkpoint(snapshot) 机制。checkpoint 会被存储为类似 B-tree 这样压缩的格式,并可以直接将数据映射到内存中,且不需要额外解析,就可以直接进行命名空间的查找。
在生成 checkpoint 时,master 会将日志滚转(生成新日志文件),并在另一个线程中开始生成 checkpoint。性能:拥有几百万的文件的 GFS 集群中,生成 checkpoint 耗时不到一分钟。
一致性模型 #
数据写入的并发保证:

- consistent: all clients will always see the same data, regardless of which replicas they read from. 所有客户端能够读取到相同的数据(也可能是数据的副本),即为一致。
- defined: a file data mutation if it is consistent and clients will see what the mutation writes in its entirety. 如果保持了一致,文件数据的改动能对客户端可见,称为已定义。
「?」Concurrent successful mutations leave the region undefined but consistent: all clients see the same data, but it may not reflect what any one mutation has written. 成功的并发写入是一致但不已定义的。
GFS 在文件变动后能保证其是确定状态的方法是:
- 以相同的写入顺序对目标数据块的所有副本更改。
- 通过数据块中的版本信息来检测副本数据由于 chunkserver 失效导致的不一致。
只有数据块的所有副本同时丢失且 GFS 来不及处理(在一分钟以内),才会真正在 GFS 中丢失数据。
系统交互 #
租约和修改顺序 #
文件修改:引起数据块中内容或元数据变动的操作,如写或追加操作。 租约:用于维护多个副本的一致性修改。
租约的原理:
- master 在几个副本中选择一个副本,并赋予其租约(lease),这块数据块就称为 primary (主数据块)。
- primary 会对所有的数据变动操作进行线性排序,其他的几个副本都使用 primary 的操作顺序进行数据变动操作。
租约机制的设计目的:最小化 master 的(并发)管理成本。
租约默认的超时时间为 60 秒,如果 primary 的数据操作比较多,可以无限期的续约(用 HeartBeat 与 master 发送续约请求)。master 可以对租约进行废除(revoke)。

数据流 #
系统创新点之一:解耦数据流和控制流,提高了网络效率。
系统目标:高效利用网络带宽,尽可能避免网络瓶颈和高延迟链路,以及推送数据延迟最小。
高效利用带宽:数据以线性的方式推送给一系列数据块服务器(就是逐一推送),而不是使用其他分布式的拓扑结构(树型等)。这样可以使得全部出带宽都用于尽可能快地传送数据,而不是发送给几个不同的接收者 这也是 feature ???感觉就是不想做 QoS 用的朴素方法啊。。。
尽可能避免网络瓶颈和高延迟链路:机器都会尽可能地发送数据给最“近”的机器。这个“近”是通过网络 IP 地址来计算的(因为网络拓扑足够简单,且按照一定规则来分配的 IP)。
推送数据延迟最小:使用 TCP 连接流水线式传输数据。由于链路使用的是全双工模式,因此 chunkserver 在收到数据后马上将数据发送出去并不会降低数据接收速度。理想情况下,发送 B 字节大小的内容给 R 个副本,需要的时间为 B/T + RL ,其中 T 是最大带宽,L 为两台机器之间的传输延迟。
解读一下 B/T + RL :B/T 为数据从一个机器传输到另一个机器的时间,而 RL 为这些副本之间各自建立连接的时间。由于采用的是流水线式传输,因此总耗时为两者之和。
原子记录追加 #
GFS 中,客户端仅能指定其想要写入的数据,而不能管理写入的偏移量(即位置)。GFS 会选定一个偏移量,以最少一次原子性的原则(at least once atomically)将数据追加写入文件。
如果写入数据会导致数据块超限(大于 64 MB),GFS 会将该数据块对齐至 64 MB(即认为该数据块不能再写数据了),并告诉其他副本也这样做,最后给客户端返回这次写操作不成功,继续对下一个数据块进行写入尝试。
快照 #
快照操作(snapshot)可用于对文件或目录进行快速复制,且能够尽可能小的影响当前的文件修改操作(mutation)。
GFS 也是用“写时复制(copy-on-write)”实现快照操作。
快照操作流程:
- master 接收到快照请求。
- master 将需要做快照的文件(目录)的数据块的现有租约全部废除(revoke)。
- master 将废除操作通过日志记录在磁盘上,接着将元数据进行复制
这块有点没看懂。 - 相关的 chunkserver 对其指定数据块执行复制操作。
master 操作 #
master 的工作:
- 执行所有关于命名空间的操作
- 数据块调度决策
- 新建数据块以及维持数据副本数
- 协调系统范围内的活动使副本数保持在设计数量
- 对数据块服务器进行负载均衡
- 清点系统内剩余空间
命名空间管理和锁 #
为了让多个操作能够在 master 上同时进行,GFS 使用命名空间的锁来保证正确的操作顺序。
GFS 保存了一个查找表,建立起全路径位置和元数据的映射,并通过前缀压缩将该查找表高效地存储在内存中。每个在命名空间树中的节点都有自己的相应的读写锁。
如果要操作 /d1/d2/.../dn/leaf ,则需要获取到 /d1, /d1/d2, …, /d1/d2/.../dn 的读锁,和 /d1/d2/.../dn/leaf 的读锁或写锁。
举个例子:
假设我们同时进行以下操作:
- 将
/home/user快照至/save/user。 - 新建文件
/home/user/foo。
| 操作 | 需要获取的读锁 | 需要获取的写锁 |
|---|---|---|
| 1 | /home, /save |
/home/user, /save/user |
| 2 | /home, /home/user |
/home/user/foo |
由于获取 /home/user 的读锁之后,不能同时获取 /home/user 的写锁进行删除、重命名、快照操作(此例中为快照操作)。因此这两个操作由于锁机制的存在会由并发变为顺序执行(顺序不一定)。
这样由于锁机制的存在,用户就可以在 GFS 中的同一个目录下进行并发修改操作。
读锁用于:防止目录被删除、重命名、或快照。 写锁用于:并发多次新建文件改为顺序新建。
由于命名空间会有很多节点,读写锁都是被惰性分配(allocated lazily),且在不被使用的时候就会将其删除(可能是为了减小 master 维护的压力)。为了防止死锁,所有的锁都会以一个固定的顺序被获取:先按照命名空间树的层级进行排序,在同级下再使用字典序排序。
副本放置 #
数据副本放置策略的目标:
- 最大化数据可靠性和可用性。
- 最大化网络带宽利用率。
数据副本不仅要放置在不同的机器上,这些机器还需要处于不同的机架(rack)当中。
这样做有两个好处:
- 当机架共享资源发生故障后,其他机架中的副本不受影响,仍然可以提供服务。
- 在读该副本数据时,可以最大限度利用多机架的带宽(理论最大带宽为多机架带宽之和)。
当然,也有坏处:在写数据到该副本中时,写流量必须要经过这些机架。但由于大部分应用都是读多写少,因此我们可以接受这样的代价。这就是一个作者主动做出的工程 trade-off。
新建,再复制,再平衡 #
数据副本会由于以下三个原因被新建出来:
- 新建数据块
- 再复制(re-replication)
- 再平衡(rebalancing)
master 新建数据块的副本放置考虑:
- 尽可能寻找小于平均磁盘利用率的 chunkserver。
- 限制每个 chunkserver “最近”新建 chunk 的个数(尽可能平摊读写流量)。
- 将副本放置在不同的机架的 chunkserver 中(spread across racks)。
再复制的触发条件:数据块的可用副本数量下降到了用户指定值以下(默认是 3)。
再复制可能的原因:
- 副本所在的 chunkserver 宕机。
- chunkserver 报告由于机器的磁盘出现故障,位于机器上的副本可能已经损坏。
- 副本数期望值升高(用户修改的操作)。
副本再复制的优先级因素:
- 当前副本数距离期望副本数量的大小,距离越大优先级越高(即 A 有 1 个副本,B 有 2 个副本,期望值都为 3 个副本。那么 A 的再复制优先级要高于 B)。
- 优先复制存有“活文件(live files)”而不是最近被删除文件(见后节的”垃圾回收“)的数据的 chunk。
- 优先复制阻塞了客户端请求的数据块。
当 master 选中了最高优先级的 chunk 并准备增加副本,新副本的放置考虑与新建副本一致。
在复制副本的过程中,还要控制复制所消耗的网络带宽,防止复制过程占用大量带宽,而挤占了客户端的请求:
- master 控制同一集群以及每个 chunkserver 发生的复制操作数量。
- chunkserver 通过调节读请求的数量来控制自己用于复制副本的网络带宽。
master 周期性地对所有副本进行再平衡:
- master 检查所有的副本分布状态后可将副本进行一定程度调整,以使系统的磁盘利用率更加平均,以及达到更好的负载均衡效果。
- 通过再平衡,master 可以优雅地处理新加入的 chunkserver ,而不是一次性将大量的数据块副本建立在其上。
- master 也要决定删除一些存在的数据副本,一般会选择删除磁盘剩余空间低于平均值的 chunkserver 上的数据副本,以平衡系统的磁盘空间利用率。
垃圾回收 #
当应用程序在 GFS 中删除文件时,删除操作会马上被 master 记录在日志中,但是真正的文件数据并不会马上被删除,而是先将其命名为一个携带删除时间的隐藏文件(以实现”回收站“功能),等到 master 开始进行周期性的命名空间扫描时,再将三天前(默认为三天,用户可配置)被主动删除的这些隐藏文件真正删除掉(此处为元数据的删除)。在这三天中,用户若希望恢复某个被删除的文件,只需将其重命名为正常文件即可。
在 master 周期性的命名空间扫描中,master 也能够识别出孤立数据块(orphaned chunks,指没有文件能够访问到的数据块),并对他们进行元数据删除。
以上描述都是元数据的删除,那么数据在 chunkserver 上如何被删除呢? 答案是通过与 master 之间的 HeartBeat 请求,chunkserver 会向 master 汇报自己的数据块及其相关信息,master 将识别出已经删除或孤立的数据块信息返回给 chunkserver,再由 chunkserver 自行将这些数据块删除。
这种“逐次存储回收”的机制相比于“立刻删除”有以下优点:
- 对于组件失效是日常的大规模分布式系统而言,这种机制简单且可靠。
- 存储回收成为了 master 常规后台作业的一部分,代价得到均摊,且 master 可以自由选择时间进行任务(如负载不高的工况进行存储回收任务)。
- 这个机制中的延迟回收时间(即”回收站“)为意外造成的删除提供了保护(可恢复)。
GFS 允许用户对不同的命名空间设置不同的复制和回收策略配置。
过时副本(stale replica)删除 #
对于每个副本数据,master 都维护一个最新的数据块版本号(chunk version number)用于区别副本数据的新旧程度。
每当 master 赋予数据块租约,该数据块的版本号就会变动(升高),且会通知所有最新的数据副本(可能是通过 primary 通知?)。
若 master 发现一个数据块的版本号比自己的还要高,则认为这个数据块可能是上次赋予租约之后失效了,因此设定更高的版本号为最新版本。
master 通过日常垃圾回收任务来删除这些过时副本数据。而在客户端询问 chunk 信息时,为了提高请求效率,master 简单认为所有的副本都是最新的。但 master 也会将最新版本信息放在响应中,客户端可在读取过时副本时校验版本号,从而发现副本数据过时。
容错和诊断 #
高可用 #
GFS 通过以下几点来实现高可用:
- 快速恢复:master 和 chunkserver 都会实时记录自己的状态,并在失效之后的几秒内重新启动(GFS 并不区分程序的常规终止还是异常终止)。
- 副本备份:GFS 默认将生成三个数据块副本,并尽可能的将其放置在不同的机架中。当数据块数量由于某些原因(chunkserver 下线、数据块副本损坏等)下降,master 会主动发起复制任务以保证数据块的数量维持在期望值。
- master 复制:master 的操作日志会被持久化至硬盘中并被备份到多个远端机器。为了简化模型,集群中只有一个 master 能够管理所有的修改操作(mutations)以及后台任务(垃圾回收等)。当 master 程序失效后,它几乎可以立刻重启程序。而若 master 所在机器出现了问题,GFS 集群外的基础设施监控
依赖外部监控检测到机器故障后,会于另一台有操作日志副本的机器启动 master 进程。客户端都使用域名来访问 master ,这样 master 可以通过 DNS 记录进行切换,而客户端并不感知。 - 影子 master (“shadow” masters):影子 master 在主 master (primary master)宕机后也能够为 GFS 提供只读功能。影子 master 会读取一个操作日志的副本,并以主 master 相同的顺序接受操作更改。与主 master 一样,它也会在启动时轮询所有的 chunkserver,以得到数据块副本位置并监控 chunkserver 的状态。在启动之后,影子 master 会很少再去进行轮询操作,仅当主 master 进行新建副本以及删除副本操作后才回重新进行轮询。
数据完整性 #
由于在 GFS 语义中,副本绝对相同这一概念是不被保证的,因此每个 chunkserver 都必须独自通过 checksum 来校验自己拥有副本的数据完整性。
校验和(checksum):每个 chunk 都被分为一群 64 KB 的 block,每个 block 都关联一个 32 位的 checksum 值。像其他元数据一样,checksum 也被保留在内存中,并通过日志持久化到磁盘中,并与真正的用户数据(data chunk)隔离。
对于读操作,chunkserver 在将真实数据返回前,会校验所有覆盖读范围数据块的 checksum 。若发现一个数据块的 checksum 与记录的不正确,则向客户端返回错误,并将这个 checksum 不匹配事件上报给 master(通过 HeartBeat ?)。当客户端收到错误后,会尝试请求另一副本进行数据读取。与此同时,master 收到事件后也会安排新的副本复制任务。当新副本复制完成后,master 还会让该 chunkserver 删除其有问题的副本数据。
checksum 对于读性能的影响非常小的原因:
- 每次读的内容都至少跨越几个小 block,因此只需要多读一点数据即可做 checksum。
- GFS 客户端通过尽可能对齐数据 checksum 的边界来减小多读数据的情况。
- checksum 查找和对比的过程并不需要 I/O 操作,且计算 checksum 的过程的同时也在发生 I/O(也就是不阻塞 I/O 操作)。
checksum 的计算对于追加写操作(GFS 最常见的场景)做了很多额外优化。
如果一个写操作要覆盖写数据块的一个部分,那么 GFS 必须要先读取其要被覆写部分头尾分块并进行校验,然后再进行覆写操作,并重新计算和记录新的 checksum。这样是为了防止”未在覆写内容但与覆写内容在同一校验块中的内容“损坏而无法被发现。
目前提及的 chunkserver 进行数据完整性保证都是被动的。除此之外,chunkserver 在空闲时会主动扫描那些很少被读取(很少活动)的数据块内容,并对其进行 checksum 计算和校验。
诊断工具 #
GFS 使用大量细节诊断日志来帮助开发者以较低的代价进行故障定位、调试、性能分析等。
GFS 服务器会生成记录了各种重要事件(chunkserver 上线下线等)的 诊断日志(diagnostic logs) 和所有 RPC 请求响应的 RPC 日志(RPC logs) 数据块内容除外。
这些日志都是顺序异步写入磁盘的,对系统的性能影响非常小,且利远远超过了弊。一些最近发生的事件也会被存在内存中以用于在线监控。
总结 #
GFS 作为 Google 上一代的分布式存储系统,可以说是很好地支撑了 Google 自身业务的飞速发展。而且,从 GFS 中我们也能够看出,正是因为多 chunkserver 的 scale-out 架构,才能降低 Google 的海量存储成本,使得公司不会因为无限膨胀的 IT 成本而被拖垮。当然,GFS 自然也是有不足的:单主模型导致其在千级节点以上的规模中,master 频繁成为系统瓶颈。这也是 Google 新一代分布式存储系统 —— Colossus,也称之为 GFS 2.0 主要解决的问题之一。多主多从架构是在分布式系统规模增大后的必经之路。当然,后续工业界陆续用了 Paxoes 以及 Raft 作为共识算法(包括 Google 的 Big Table、Spanner 等) , 使得分布式集群自身即可进行选主,极大提高了集群的自愈能力和扩展能力。