MIT 6.824 · Lecture 1: Introduction #
MIT 6.824(Distributed Systems Engineering) Lecture 1.
Paper: https://github.com/Triple-Z/paper-reading/issues/1
Lecture Notes: https://pdos.csail.mit.edu/6.824/notes/l01.txt
Lab 1: MapReduce (https://pdos.csail.mit.edu/6.824/labs/lab-mr.html)
About course #
Lectures: big ideas
Papers are for case study.
Four labs:
- mapreduce
- replication using raft
- replicated key-value service
- sharded key-value service
Why distributed systems are popular? #
- connect physically seperated machines -> sharing
- increase capacity -> parallelism
- tolerate faults -> replication
- achieve security -> isolation
Challenges in distributed systems #
- many concurrent parts (complexity)
- must deal with partial failure (complexity)
- tricky to realize the prefermance benefits
Focus in the class: Infrastracture #
- Storage (e.g. GFS)
- Computation (e.g. mapreduce)
- Communitation (e.g. RPC, more on MIT 6.829 Network Systems)
Main topics #
- Fault tolerance
- avaliablity (replication)
- recoverability (logging / transactions, durable storage)
- Consistency
- Performance (throuhtput, latency)
- Implementation
Achieving these three at the same time is extreme difficult. There always a trade-off.
MapReduce context #
- Multi-hours computations on terabytes data (web indexing)
- Goal: easy for non-expertise to write distributed applicaitons
- Approach:
- map + reduce -> sequential code
- MR deals with all the distributioness
This library is not in general purpose, your computational model has to fit in that paricular computational model which is provided by MapReduce.
Abstract view #
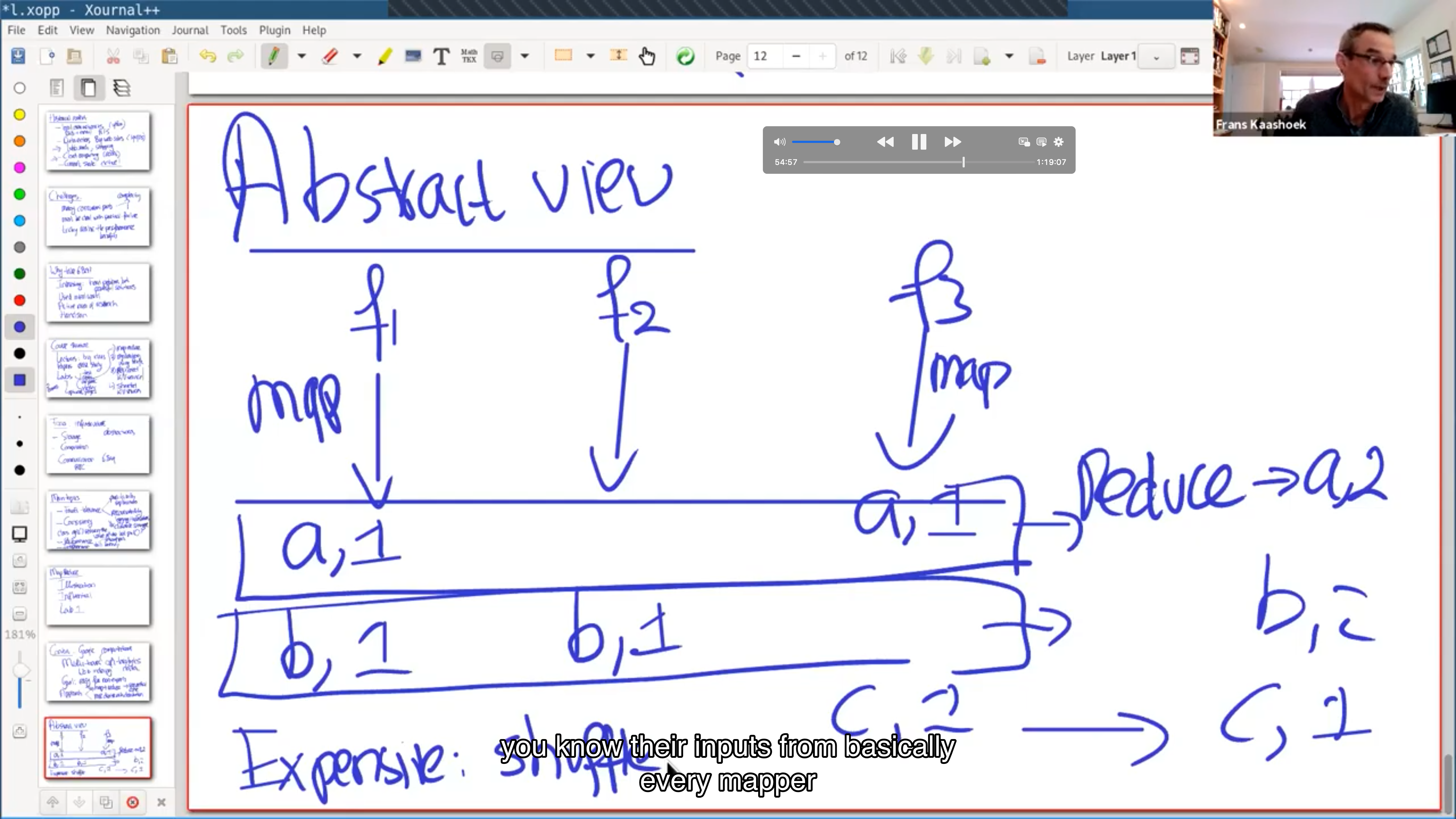
MapReduce execution overview #
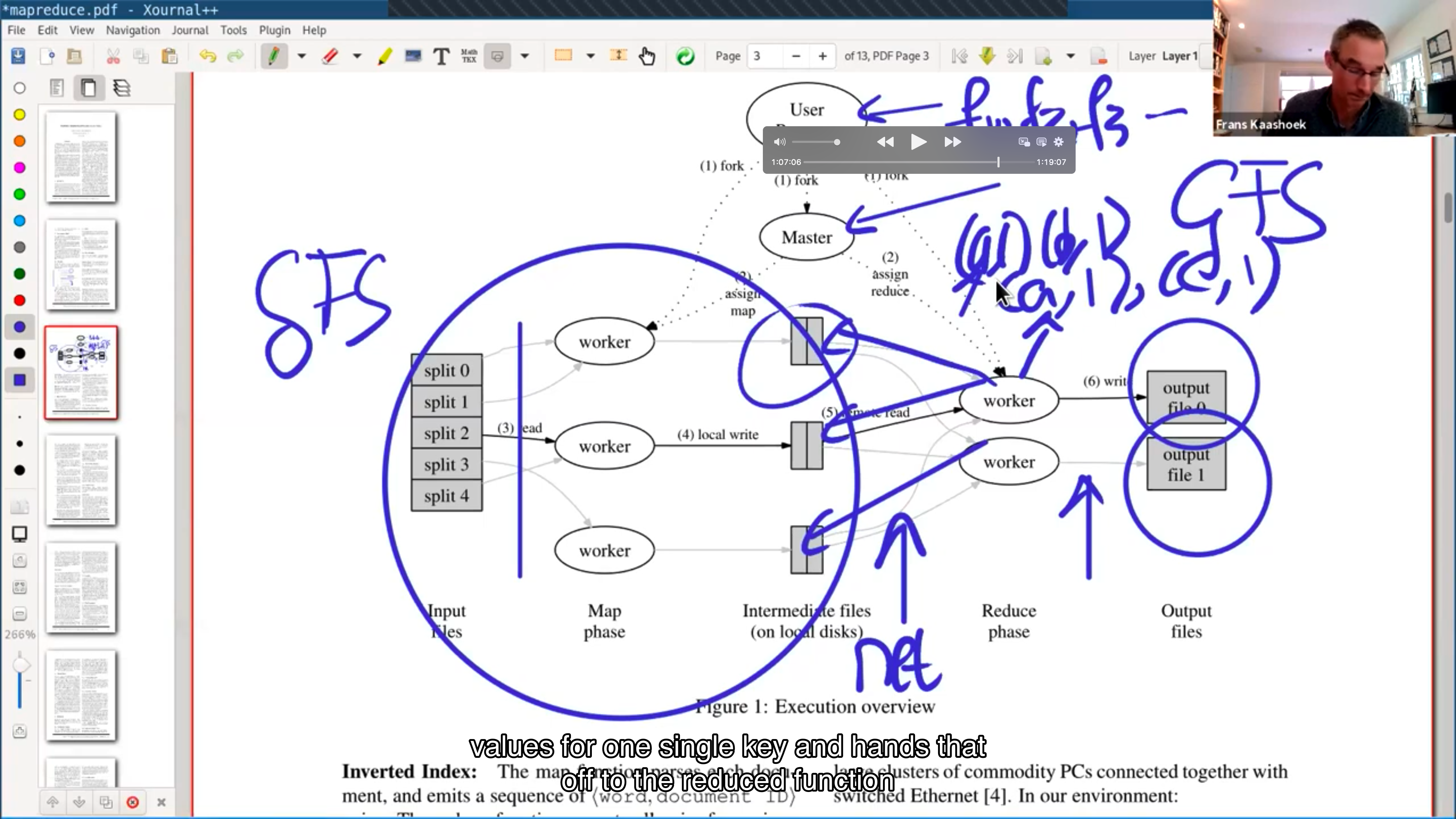
Fault tolerance #
Coordinator rerun map/reduce.
Can map function run twice? Yes.
functional aspect is important, map function should be functional / determinsitic(any node run this funciton can get the exactly same result).
Can reduce run twice? Yes. Rely on the Atomic Rename on GFS.
Can coordinator (master) fail? No. If coordinator fail, the whole job must rerun.
How to deal with slow workers (stragglers)? Do backup task, run the map/reduce task on the other worker. Therefore the performance is not limited by the slowest worker, but basically the fastest of the ones that got replicated.
This is the common idea to deal with the stragglers or to deal with tail latency, is trying to replicate task and go for the first that finishes.